Break The Rules to Avoid Breaking the Limits
As a Salesforce developer you know all about governor limits (if you don't know about them but call yourself a Salesforce developer you should go and read this right now). Earlier on in the life of the platform I used to tell people that learning how to manage the governor limits was the thing you had to learn when moving from another development stack (these days just keeping up with it is the hardest part). Working on the platform itself isn't intrinsically difficult, but it's hard to do if you don't learn the rules.
The limit most often his is probably that which says you can only perform 100 SOQL querys in a given execution context, and that's largely down to people putting queries inside for loops. Almost every developer that's new to the platform will learn about this limit the hard way.
Two of the governor limits that aren't often hit are the CPU time limit of 10 seconds (at the time of writing) and the heap size limit of 6MB. Typically you'll only hit the first if you've accidentally created an infinite loop, but the latter can be a little trickier. Either you're processing a serious amount of records (especially given that if you're in an asynchronous context such as a batch the limit is doubled) or you're dealing with larger chunks of data, such as files.
First Things First, What is the Heap?
These days it wouldn't surprise me if a lot of programmers had never even heard of the terms stack and heap; JavaScript and it's ilk have provided something of an 'easier' path to writing code than traditional environments. Don't get me wrong, this is a good thing, but it does mean that some coders may miss out on key concepts. Yes your language abstracts the technical details for you, but knowing what it's doing underneath is quite beneficial when things start to break. In case you weren't aware, JavaScript too has a heap, and you can exhaust it.
An analogy I've heard before is that to drive a car you don't need to know how the engine works, and that is perfectly true, but it's definitely beneficial to understand that it burns fuel, and that you need to put fuel in the tank. If you knew as much as an auto mechanic you'd be in a great place should you ever notice that your car isn't performing as it should, and that's where a programmer with a deep understanding of a system has an advantage over one who doesn't.
Get To the Point: What is the Heap?
Ok ok, the point. Programs on nearly every platform out there make use of two memory pools, the stack and heap. The Stack is a memory structure used to store variables used in functions, parameters passed to them, and other handy things like the value of the program counter when functions are called (you definitely don't need to know what this is on the Salesforce platform but suffice to say you wouldn't be doing much without it!).
The heap is a big chunk of memory which in languages such as C can be allocated dynamically at run time as required. In other words, you ask the system for a chunk of memory N bytes in size, and if it's got it, it gives it to you. In Java, and by extension Apex, the heap is where all Objects are stored.
So when you create a new instance of Account, like this:
Account a = new Account();
The memory used to store it is from the heap. You've started your crawl towards hitting the heap size governor limit, but you're still a long way off. By logging the heap usage before and after (by calling Limits.getHeapSize() to get the usage and Limits.getLimitHeapSize() to get the limit) we can see that this takes up 4 bytes from the heap:
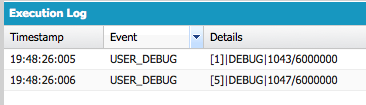
Heap usage before and after creating an account in memory
The more information we need to keep around for the lifetime of our execution context, the more heap space we consume. Assigning a name to our account instance:
a.Name = 'Lacey Inc';
consumes more of the heap (in this case assigning 'Lacey Inc' takes up 17 more bytes, an empty string takes 8).
Avoiding The Limit
There are some tried and tested ways to avoid hitting the limit, and the platform documentation lists some of the ones built into the platform. For instance, if you had 500 contacts in your org and ran some code like this:
List<Contact> contacts = [select Id, FirstName from Contact];
for(Contact c : contacts)
{
// do some processing
}
The whole list of 500 contacts would be in memory (and thus consuming heap space) for the duration of this codes execution, and would be continued to be used until the method containing it returned.
If you refactored the code to look like this:
for(List<Contact> contacts : [select Id, FirstName from Contact])
{
for(Contact c : contacts)
{
// do some processing
}
}
then the platform would automatically break down the results of the query into lists of 200 records, i.e. in this scenario the inner loop would run three times, twice on lists of 200 contacts, and then once on the remaining 100 contacts.
Generally you only want to keep things around that you need to work with: if you need to query and process a list of records in a specific method then create that list variable inside that method, don't use a class property unless that list is needed elsewhere.
So What About Breaking the Rules?
This is where things got interesting for us recently. @Bachovksi was working on a feature that required a search and replace on a long String, where short sections of the String were being replaced with base 64 encoded image data from Attachments, which naturally was quite large in comparison to the Strings handled in more typical CRM scenarios.
Querying for the Attachment bodies and then working on the String in a manner roughly like this:
List<Attachment> attachments = [select Id, Body from Attachment where ParentId = : someRecordId];
for(Attachment a : attachments)
{
theString.replace(a.Id, a.Body);
}
meant that the attachment bodies were effectively taking up space on the heap twice, they were stored in the Attachment objects within the list, and as the theString expanded they were taking up space there too. This imposed a reasonably tight limit on the amount of replacement we could perform. By putting our heads together and breaking the rule of not putting queries inside of loops like this pseudo-code shows:
for(Id attachmentId : attachmentIds)
{
String body = [select Body from Attachment where Id = :attachmentId].Body;
theString.replace(attachmentId, body);
}
we could generate a much larger String as we didn't need to retain space on the heap for all of the attachment bodies as well as the resulting String, we only needed space for the String and one body at a time. This almost doubled the amount of data we could process and include.
Yes, we ended up being able to support far more by doing some image processing in JavaScript before even hitting the platform making all of this somewhat moot, but I believe this is the first time in 7 years of working on the platform that I've seen a legitimate reason to break one of the golden rules.
If David Crane had used the Atari 2600 as the engineers who created it intended we'd never have seen the likes of Pitfall. It's often important to remember that although the well known rules of a given technology should guide your thinking, they shouldn't constrain it: in reality they're often guidelines.