The Elusive Many-to-Many Simple Relationship: Extreme Data Hackery
Guest post by Jeremy Kraybill

Today's post is a rather epic guest post from my buddy Jeremy Kraybill, who is most definitely a veteran of the Force.com platform and somebody I'm constantly learning from.
Jeremy is the developer behind Dashcord, a marketing automation application for Salesforce that's 100% native; we run it at S. P. Keasey and I can't recommend it enough, yet we're only using a fraction of it's functionality and power.
This post is based on a presentation Jeremy did at our last Melbourne Developer User Group meet up that consisted of some serious whiteboard action. For the record, the 'WARNINGS' were from Jeremy, not me!
Extreme Data Hackery and Geeky Data Structures
WARNING: this article contains theoretical, (poorly) pseudocoded, hackish solutions to problems that most people do not have. Only read on if you are entertained by such things.
I recently came across an interesting data modelling challenge that involved some challenges fairly unique to the platform. Here at Dashcord, we deal with marketing automation, and the hub of that activity in our world is the Campaigns tab, and data that deals with CampaignMember objects.
The Campaign-CampaignMember relationship in Salesforce is a fairly straightforward master-detail type relationship:
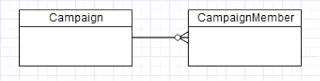
A Campaign may have 0 or more CampaignMember objects. Each CampaignMember, in turn, points to exactly one Contact or Lead record. So a Campaign, at its heart, is just a collection of Contact and/or Lead records, with optional data (like Campaign Name, Type, Date, etc.) at the Campaign level, and optional data (like attendance status, feedback, activity) at the CampaignMember level.
A very common activity for customers is to record some sort of activities below Campaigns. These vary from physical activities like events, webinars, physical mailings, to electronic interactions like outbound emails, website interactions (clicks, landing page interactions, forms filled out, etc.). For the sake of simplicity, let’s model that as a single child custom object called “CampaignEvent” under Campaign:
]
So now we can record these activities under the umbrella of a Campaign, and we have a record of what we did for each Campaign.
The very next thing customers frequently want to do is capture involvement in those activities. Who showed up to each event? Who opened a given email, or maybe more specifically clicked through a specific link in an email or filled out the landing page form that was promoted?
A data modeller new to Salesforce would see that we are talking about a many-to-many relationship between CampaignEvent and CampaignMember. Let’s call it MemberEvent:
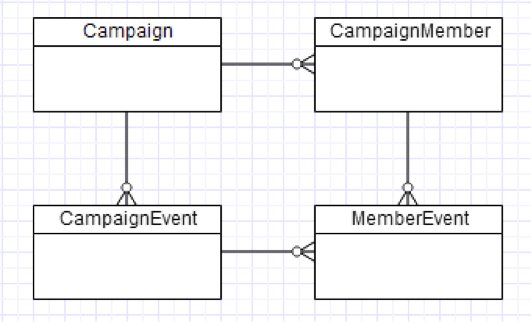
In most data systems, that wouldn’t be a problem at all. MemberEvent records the fact that a given CampaignMember had a relationship to the event. The existence of that relationship may be all that we’re interested in (did the person open the email / attend the event / visit our website?) – and frequently is. Conveniently, you could also record other details on MemberEvent, like attended status, number of interactions, etc.
Not so fast...
If you’ve been around the Salesforce standard object model enough, you’ll realize there are two problems with that approach.
First, CampaignMember objects cannot be used in Lookup or Master-Detail relationships. This is a legacy issue that’s been around for a long time, and is well-documented (“Lookup relationships from objects related to the campaign member object aren’t supported” . CampaignMember can contain lookup relationships to other objects, but since we need a one-to-many from CampaignMember to MemberEvent, the best we could do there would be to create a whole bunch of lookups on CampaignMember that point to MemberEvent1, MemberEvent2, etc. It’s inelegant and doesn’t at all scale to more than a handful of relationships.
Second, even if it was feasible, Many-to-Many relationship objects in Salesforce are prohibitively expensive. When you create a custom object, even if it contains no data beyond a couple of lookup fields, your data storage quota is “charged” 2 kilobytes per record. If you’re dealing with thousands of CampaignMembers, and dozens of hundreds of interactions per Campaign, you could easily start seeing your Salesforce data usage ballooning by literally hundreds of megabytes or more per Campaign. That can get expensive for customers who aren’t into the thousands of Salesforce seats, and is a steep price to pay for a tiny amount of actual data.
This is a very specific example of a common data modelling challenge in Salesforce orgs: the elusive Many-to-Many simple relationship. In my days as a Salesforce consultant, almost every customer I dealt with ran into this problem in some area of their data model.
Simply put, the Many-to-Many simple relationship challenge in Salesforce can be expressed like so:
“We need a way to record the existence of a relationship between any number of object A and any number of object B without blowing up our data allowance.”
It’s not a trivial problem, and it doesn’t really have an elegant solution. However, there are a couple variants of this requirement that do have theoretical hackish solutions with a little bit of Apex code.
The approach has to do with a compromise in the customer requirements, but a compromise that’s common. The customer wants to know how many relationships exist between object A and object B (in this example, CampaignMember and MemberEvent), but doesn’t require strict accuracy in numbers; specifically, a small amount (say on the order of a few percent of total data) of under-reporting of the number is fine, especially if similar numbers are comparable across events.
I came up with a novel idea for dealing with this type of requirement. It’s somewhat of a data hack, and I’m presenting it here as a thought experiment rather than a best practice, but hopefully some code nerds out there like me find it interesting.
What if you used long text area fields as a kind of poor man’s data store?
I’ve seen quite a few variants of this strategy at client sites in the past, and it takes advantage of a loophole in the platform’s data accounting strategy. (Of course, as such, the loophole could – and probably will – close at some future point.) This loophole is that custom object data storage is fixed at 2k per record, regardless of the actual data per record. This is usually bad – you get charged 2k for that many-to-many record that only has a few bytes of data – but it also gives you the ability to stash more than 2k of data on a single record.
I’ve seen some interesting approaches to this platform “feature” in the past—practices like storing entire JSON representations of objects in long textareas at insert/update time to reduce processing load for REST integrations, for instance, or storing hidden record-specific error logs. What if we applied that approach to our problem at hand?
The Bitset
A bitset or bit array is just a simple array of bits: [0,1,0,0,0,1,0,1] is an example. They’re used widely in computing, but usually in much lower-level languages than Apex. Think of them as the equivalent of a whole bunch of Salesforce checkboxes. How can we apply these to our problem? Let’s instantiate the contents of a new custom long text field, Poormans_Bitset__c, with 32,768 zeroes in Apex (the largest size for a long text area):
public static Integer SIZE = 32768;
// snip
myObj.Poormans_Bitset__c = '0'.repeat(SIZE);
Now let’s manipulate one of its “bits” to 1:
Integer ind = 999; // our target array index
myObj.Poormans_Bitset__c = myObj.Poormans_Bitset__c.substring(0, ind) + '1' + myObj.Poormans_Bitset__c.substring(ind + 1, SIZE);
Now we can test for the value of one of those bits:
String aBit = myObj.Poormans_Bitset__c.mid(999, 1); // '1'
So now we’re able to access the data equivalent of 32,768 checkboxes worth of data in a single text field. That’s kind of cool; although it’s very inefficient data-wise, on the platform there are times where doing this would be kind of useful.
Using strings to only store “0” or “1” is also inefficient; if you needed to store more data, but didn’t care as much about how much work it took to count the “1”s in a bitset, it’s possible that you could do something like use a custom encoding, or use the platform’s base64 encoder, to get 6+ bits of storage per character (so one textarea would give you 196,000+ checkboxes worth of data) – probably 8 bits per character with a little more fancy programming.
You could envision a little utility wrapper around text area fields that would look something like this:
public Interface Bitset
{
public void init(); // inits an empty all-‘0’ string
public void init(String src); // from a pre-existing string
public Boolean getValue(Integer index); // returns true if ‘1’
public void setValue(Integer index, Boolean value);
public String toString(); // persistable
}
Depending on the implementation, you could store somewhere between 32k and 256k Boolean values in a single object text area field.
Bringing it Back to the Problem
So how could we use our new poor man’s bit set to the problem at hand? Let’s say you wanted to record a simple many-to-many relationship between object A and object B, where you just needed to know that a relationship exists or not. If you created a textarea-based bitset on one of the objects (probably the one with the “larger” side of the relationship), you could now use the hashCode of the related object to get an index into the bitset:
Bitset myBitset = BitsetImpl.init(objectA.Poormans_Bitset__c);
// translate objectB’s ID into a value from 0 to 32767
Integer index = Math.mod(Math.abs(objectB.Id.hashCode()), 32768);
// set the value of the bitset at that index to true
myBitset.setValue(index, true);
Now your bitset contains a mostly-accurate picture of which members of objectB any instance of objectA have a relationship to.
How accurate? I ran a quick Monte Carlo simulation using random data and found that with a 32k element bitset, you could store up to about 1000 bits with a 1% error rate (i.e. you’ll see 990 relationships instead of 1000), 3000 bits with a 5% error rate, and close to 7000 bits with a 10% error rate. If you were to use a more deterministic indexing method than hashcode (like auto-incrementing an index on your related records), you could make error-free use of the full 32,768 bits as long as one side of your relationship never contained more than 32,768 members.
For the uninformed, what does that hashCode() line above do? Well, hashCode() is a system function that translates any object’s value into an Integer. It’s used all over the place in system internals of Java, and as a result, Apex, but is mostly hidden to the average programmer. It’s worth reading about—it’s a fundamental computer science concept, and one that I as a non-CS grad had to teach myself when I was thrown into my first Java development job—but all you really need to know is that it always gives you the same number for the same input.
Because we can move from any arbitrary value (in this case, a Salesforce ID, but it could be anything) to an arbitrary number, and then take that number and convert it to a value that fits our bit set, we can test for membership in our set—and keep a fairly accurate count of those potentially huge numbers of relationships we care about—on the cheap.
What if you don’t care about the count, but just about membership?
WARNING: if you found the earlier part of this article laughably theoretical and boring, don’t read on, because it gets worse.
I’ve also come across some novel requirements in the past where you don’t care about a total set ownership number, but you just need to answer this question:
“is this element definitely NOT a member of this given set?”
Examples of tests like this are where you have a big set of potential arbitrary data, but it has sparse membership, but testing for membership saves you an expensive operation. A contrived example would be that a customer can be presented with any one of thousands of product offers via a website; customers can be presented with one offer per site visit, and presenting a customer with a repeated offer that was previously declined is something you need to avoid.
Another example would be where you have some expensive-to-generate data (say dynamic PDF reports) sitting in an external data store (like Amazon S3) and want to be able to immediately determine if you possibly have the pre-calculated version sitting in your data store without making a call to the data store every time someone requests the data.
A property of these scenarios is that they may be mapping arbitrary, unknown data—like user-requested report parameters or dynamic products that are not known to the system that has to make decisions about them. So there may not even be a relationship that could be modelled without storing a huge number of entities that the decision-making system needs to explicitly know about.
Enter the Bloom Filter. It’s a novel data structure that uses bit sets to test membership (see http://en.wikipedia.org/wiki/Bloom_filter for the nitty gritty details). Rather than computing a single hash index value (say, using the hash of the request parameters), you compute several hashes:
Integer ind1 = Math.mod(Math.abs(requestUrl.hashCode()), 32768);
Integer ind2 = Math.mod(hashcode2(requestUrl)), 32768);
Integer ind3 = Math.mod(hashcode3(requestUrl)), 32768);
If (!myBitset.getValue(ind) && !myBitset.getValue(ind2) && !myBitset.getValue(ind3)) {
// definitely not cached; skip an S3 call and just generate the report and store it.
} else {
// check S3, it’s probably there
}
// set our filter for future reads
myBitset.setValue(ind1, true);
myBitset.setValue(ind2, true);
myBitset.setValue(ind3, true);
Your alternate hash functions “hashcode2” and “hashcode3” are variants on the standard String hash function. In Java, I created some test functions simply by copying the core String implementation and using different prime numbers.
The cool feature of Bloom Filters is that they support a much higher density of data with a lower false positive rate than a simple one-hash index; I did a Monte Carlo simulation using my simple variants on the Java String hashcode function and got these error rates on a 32k bitset for different numbers of hash functions:
| 1-hash (not a Bloom filter) | 2-hash | 3-hash | 4-hash | |
| Error Rates | ||||
| 1% | 892 | 2760 | 4391 | 5202 |
| 2% | 1320 | 4457 | 5948 | 6076 |
| 5% | 3022 | 7515 | 8655 | 8468 |
| 10% | 6780 | 11547 | 11855 | 11385 |
So per the above table, a 4-hash Bloom Filter with 32k bits could accommodate almost 6x as many elements (5202) as a simple 1-hash filter (892) with a <1% false positive rate. As you can see, depending on your tolerance for error vs accuracy, and your data volume, picking the right type and size of Bloom Filter would be important!
That’s all, folks
Well if you’ve read this far, thanks for totally geeking out with me and talking about theoretical ill-advised impractical solutions to unlikely and possibly non-existent problems! Seriously though, if you found any of this interesting, I definitely recommend reading more about Bloom Filters, hash functions, and digging into the innards of the Java implementations of things like HashMap and even String—if you found this article readable you will likely find those things interesting!